









Μάθε περισσότερα για το τμήμα

































Επικαιρότητα
16-04
2024
2024
11-04
2024
2024
10-04
2024
2024
Σημαντικές Διακρίσεις







Πρόγραμμα Υποτροφιών
«Η Σάμος στηρίζει τους φοιτητές της»

Επαγγελματική Αποκατάσταση Αποφοίτων Τμήματος
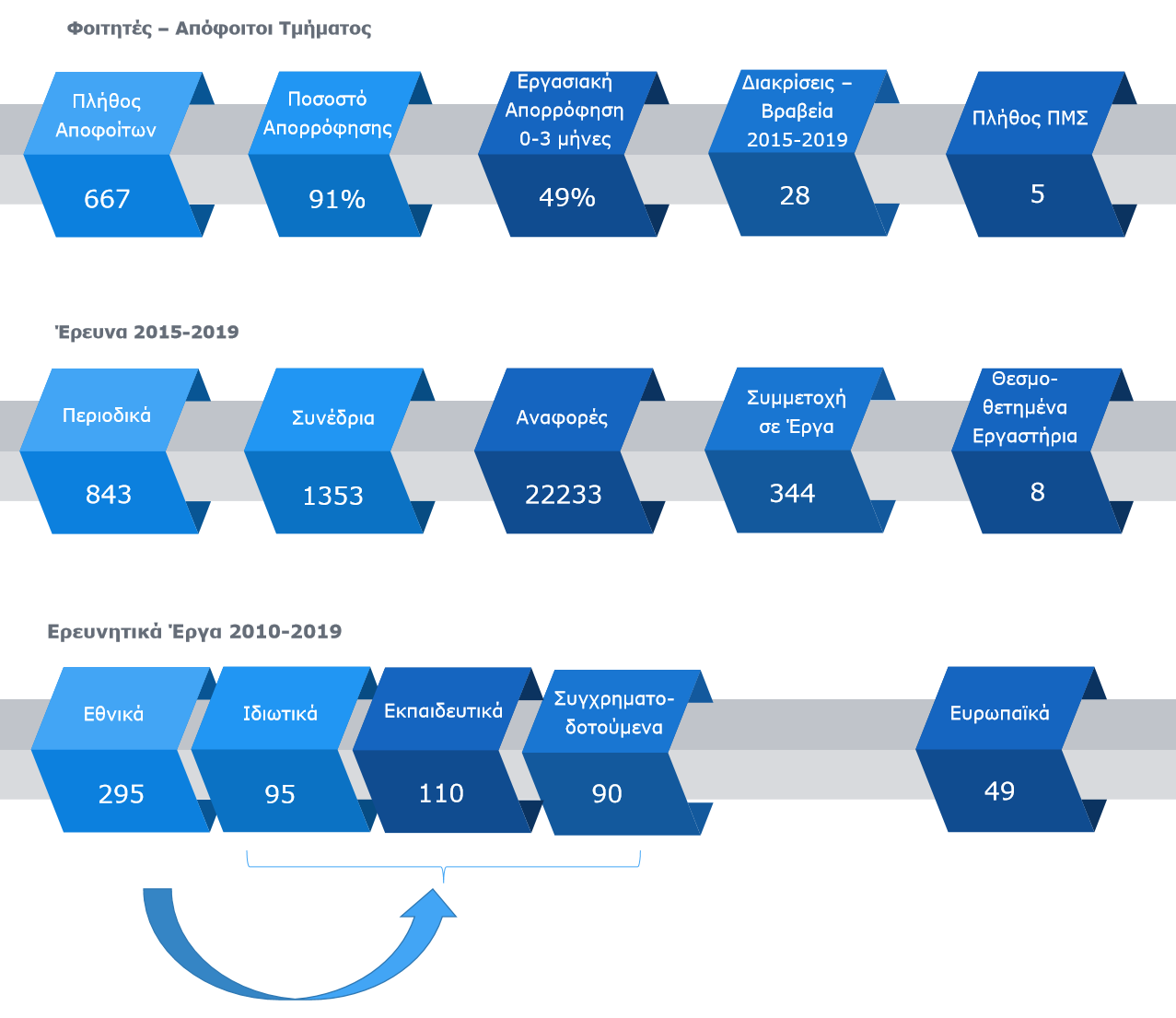
Έρευνα επαγγελματικής αποκατάστασης Αποφοίτων (2019)
Ζω στη Σάμο

Σπουδάζω στη Σάμο, σπουδάζω στο Τμήμα Μηχανικών Πληροφοριακών και Επικοινωνιακών Συστημάτων του Πανεπιστημίου Αιγαίου.
Περισσότερα ...
Τοποθεσία
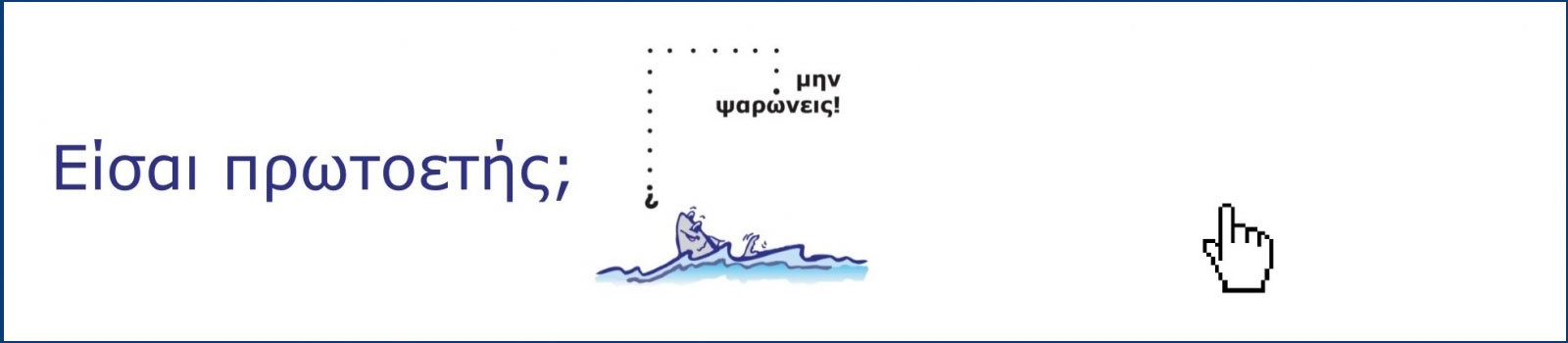
Είσαι Πρωτοετής;
Αν είσαι πρωτοετής ακολούθησε τον σύνδεσμο της παρακάτω εικόνας και ενημερώσου για ότι σε αφορά από τον Οδηγό Εισακτέων Πρωτοετών
Συμβουλευτικός Σταθμός Σάμου
| Που στεγάζεται | Οι συνεδρίες γίνονται πλέον διαδικτυακά. |
|---|---|
| Ψυχολόγος | Δέσποινα Τσουβαλά | Επικοινωνία | E-mail: symvouleutikos-stathmos-samou@aegean.gr |
Πρόγραμμα Υποτροφιών
«Η Σάμος στηρίζει τους φοιτητές της»
Επαγγελματική Αποκατάσταση Αποφοίτων Τμήματος
Έρευνα επαγγελματικής αποκατάστασης Αποφοίτων (2019)
Ζω στη Σάμο
Σπουδάζω στη Σάμο, σπουδάζω στο Τμήμα Μηχανικών Πληροφοριακών και Επικοινωνιακών Συστημάτων του Πανεπιστημίου Αιγαίου.
Περισσότερα ...
Τοποθεσία
Είσαι Πρωτοετής;
Αν είσαι πρωτοετής ακολούθησε τον σύνδεσμο της παρακάτω εικόνας και ενημερώσου για ότι σε αφορά από τον Οδηγό Εισακτέων Πρωτοετών
Συμβουλευτικός Σταθμός Σάμου
| Που στεγάζεται | Οι συνεδρίες γίνονται πλέον διαδικτυακά. |
|---|---|
| Ψυχολόγος | Δέσποινα Τσουβαλά | Επικοινωνία | E-mail: symvouleutikos-stathmos-samou@aegean.gr |